AIAI AgentsAWSAmazon
Amazon Bedrock for Beginners: From First Prompt to Production-Ready AI Agents
🤖 Amazon Bedrock for Beginners: From First Prompt to Production-Ready AI Agents
TL;DR: This guide walks you from your first Amazon Bedrock API call to building production-grade AI agents using tools, RAG, and guardrails. You’ll learn how to design scalable, cost-efficient AI systems without managing infrastructure—and understand what’s actually happening under the hood.
🎯 Dynamic Intro
You’ve probably felt it: adding AI to an application sounds deceptively simple—“just call a model API and you're done.” But the moment you start building, the illusion collapses. Suddenly you're juggling model selection, prompt design, cost control, latency, data integration, and security.
This is where most developers stall—not because AI is too complex, but because the ecosystem is fragmented. Different providers, inconsistent APIs, infrastructure overhead, and unclear patterns make it hard to move from idea to production.
Amazon Bedrock changes that equation. It abstracts away infrastructure, standardizes access to multiple foundation models, and gives you production-ready building blocks—like RAG, tool use, and guardrails—under one roof.
In this tutorial, you’ll go beyond “hello world.” You’ll learn how to:
- Run your first inference call
- Build multi-turn conversational systems
- Integrate external tools and APIs
- Implement RAG with Knowledge Bases
- Add enterprise-grade safety with guardrails
- Combine everything into a fully autonomous AI agent
💡 The "Why Now"
We’re at an inflection point in software engineering. AI is no longer a feature—it’s becoming the interface layer of modern applications.
According to industry trends:
- Over 70% of SaaS platforms are integrating AI capabilities
- LLM usage has grown 10x year-over-year in enterprise environments
- AI-native startups are shipping products 3–5x faster than traditional teams
But here’s the catch: most teams are still stuck in prototype mode. They can demo AI, but they can’t scale it reliably.
Why?
Because building AI systems isn’t just about models—it’s about systems design:
- Where does data come from?
- How do you ensure accuracy?
- How do you prevent hallucinations?
- How do you keep costs under control?
This is where Amazon Bedrock becomes critical. Instead of stitching together:
- OpenAI APIs
- Vector databases
- Custom orchestration layers
- Safety filters
You get a unified AI platform that handles:
- Model access (Claude, Llama, Mistral, Titan)
- Retrieval (Knowledge Bases)
- Orchestration (Agents)
- Safety (Guardrails)
Think of Bedrock as the AWS Lambda moment for AI—you stop managing infrastructure and start focusing on logic.
🏗️ Deep Technical Dive
Let’s peel back the abstraction layers and understand how Bedrock actually works.
🧠 Inference with the Converse API
At the core of everything is inference—sending a prompt and receiving a response.
import boto3
client = boto3.client("bedrock-runtime", region_name="us-east-1")
response = client.converse(
modelId="us.amazon.nova-lite-v1:0",
messages=[
{"role": "user", "content": [{"text": "Explain serverless computing"}]}
],
inferenceConfig={"temperature": 0.7, "maxTokens": 500}
)
print(response['output']['message']['content'][0]['text'])
This unified API is powerful because:
- ⚡ Model-agnostic → swap models without changing code
- 🧩 Standardized schema → consistent request/response format
- 💰 Token visibility → built-in cost tracking
🔄 Multi-Turn Conversation Architecture
Here’s the critical insight: LLMs are stateless.
Every request must include:
- Previous messages
- System instructions
- Context
conversation = []
conversation.append({"role": "user", "content": [{"text": "Suggest dinner"}]})
# append assistant response...
# repeat
This creates a hidden cost:
- 📊 More context = more tokens = higher cost
- ⚡ Larger payloads = higher latency
Production pattern:
- Store conversation in DB
- Trim history intelligently
- Use summarization for long threads
🧩 Tool Use (Function Calling)
LLMs alone are read-only intelligence. Tools make them actionable.
Instead of guessing:
“What’s the weather?”
The model can:
- Request a tool
- Get real data
- Respond accurately
def get_weather(location):
return {"temp": "25°C", "condition": "Sunny"}
Tool flow:
- Model → requests tool
- App → executes function
- App → returns result
- Model → generates final answer
This is the foundation of AI agents.
🔍 Retrieval-Augmented Generation (RAG)
RAG solves the biggest problem in AI: hallucination.
Pipeline:
- Convert documents → embeddings
- Store in vector DB
- Query → semantic search
- Inject into prompt
With Bedrock Knowledge Bases:
- ☁️ No vector DB setup
- ⚡ Managed embeddings
- 📦 One API call
response = client.retrieve_and_generate(
input={"text": "When is enrollment deadline?"}
)
🛡️ Guardrails (Safety Layer)
AI without safety is a liability.
Guardrails provide:
- 🚫 Content filtering
- 🔐 PII masking
- 🎯 Topic restriction
- 🧠 Hallucination checks
guardrailConfig={
'guardrailIdentifier': 'id',
'guardrailVersion': '1'
}
This operates outside the prompt, making it:
- More reliable
- Harder to bypass
- Consistent across models
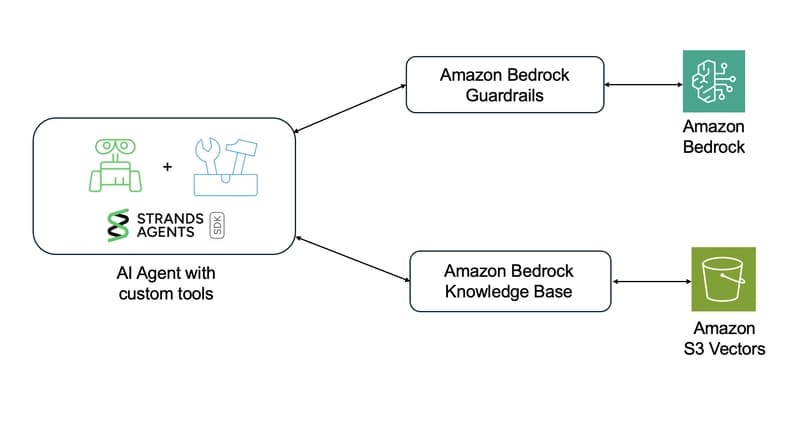
⚙️ Agent Architecture (The Final Layer)
Agents combine everything:
- Memory
- Tools
- RAG
- Reasoning loops
Instead of:
One request → one response
You get:
Think → Act → Observe → Repeat
With frameworks like Strands:
agent = Agent(
model=bedrock_model,
tools=[retrieve, lookup_course]
)
response = agent("When is CS101 class?")
📊 Real-World Applications & Case Studies
Amazon Bedrock isn’t theoretical—it’s already powering production systems across industries.
Enterprise Knowledge Assistants
Companies are replacing internal search tools with AI copilots:
- Employees query policies in natural language
- RAG ensures accuracy
- Guardrails prevent leaks
Customer Support Automation
AI chatbots now:
- Resolve 60–80% of queries
- Access CRM data via tools
- Maintain conversation context
FinTech Decision Systems
Banks use Bedrock to:
- Analyze documents
- Detect fraud patterns
- Generate compliance reports
EdTech AI Tutors
Like our university chatbot example:
- Personalized learning assistance
- Real-time data access
- Course scheduling via tools
The pattern is consistent: LLM + Data + Tools = Real Value
⚡ Performance, Trade-offs & Best Practices
Key Considerations
- ⚡ Latency vs Accuracy → Larger models are slower but smarter
- 💰 Token Costs → Optimize prompt size aggressively
- 🔄 State Management → Avoid sending full history every time
- 🧠 Model Selection → Use small models when possible
- 📦 Caching → Reuse repeated prompts
Deep Insight
The biggest mistake teams make is treating LLMs like APIs instead of distributed systems.
AI systems require:
- Observability
- Rate limiting
- Cost monitoring
- Failover strategies
Expert Tip: Always start with the smallest viable model and scale up only when necessary. Most applications don’t need GPT-4-level intelligence—they need consistency, speed, and cost efficiency.
🔑 Key Takeaways
- 🚀 Bedrock abstracts infrastructure, letting you focus on logic
- 🧠 LLMs are stateless—context management is your responsibility
- 🔍 RAG is essential for production-grade accuracy
- 🧩 Tools turn AI from passive to actionable
- 🛡️ Guardrails are non-negotiable for real-world apps
- ⚡ Token optimization directly impacts cost and latency
- 🌱 Agents are the future of AI application design
- 🎯 Start simple, then layer complexity progressively
🚀 Future Outlook
The next 12–24 months will redefine how we build software.
We’re moving toward:
- Autonomous agents replacing traditional workflows
- Multi-agent systems collaborating like microservices
- AI-native interfaces replacing UI-heavy applications
Amazon Bedrock is positioning itself as the control plane for AI systems, much like AWS did for cloud computing.
Expect:
- Better orchestration frameworks
- More specialized models
- Deeper enterprise integrations
The real shift isn’t AI replacing developers—it’s developers becoming AI system architects.
❓ FAQ
💬 What is Amazon Bedrock in simple terms?
Amazon Bedrock is a managed AWS service that lets you access multiple AI models via API without handling infrastructure. It also provides tools like RAG, guardrails, and agents to build production-ready AI systems.
🔍 How is Bedrock different from OpenAI API?
Bedrock is multi-model and enterprise-focused:
- Supports multiple providers
- Built-in RAG and safety features
- Deep AWS integration
⚙️ Do I need a vector database for RAG?
No. Bedrock Knowledge Bases handle:
- Chunking
- Embeddings
- Storage
- Retrieval
All automatically.
💰 How much does Bedrock cost?
You pay per token:
- Input tokens (prompt)
- Output tokens (response)
Costs vary by model, so optimization is critical.
🧠 What is an AI agent in Bedrock?
An agent is a system that:
- Uses tools
- Accesses data
- Maintains context
- Executes multi-step reasoning
🎬 Conclusion
Building AI applications used to feel like assembling a spaceship from spare parts—complex, fragile, and hard to scale. Amazon Bedrock flips that narrative. It gives you a cohesive platform where models, data, orchestration, and safety all work together seamlessly.
But the real advantage isn’t just convenience—it’s clarity. Once you understand how inference, RAG, tools, and agents fit together, you stop experimenting and start engineering.
If you’re serious about building AI-powered products, don’t just copy examples—internalize the architecture. That’s what separates demos from production systems.
Explore more deep dives like this on BitAI—and start building systems that don’t just use AI, but are designed around it.
Share This Bit