GPT-5.5 vs Claude Opus 4.7: The Real Battle Isn’t What You Think
BitAI Team
May 01, 2026
5 min read
🚀 Quick Answer
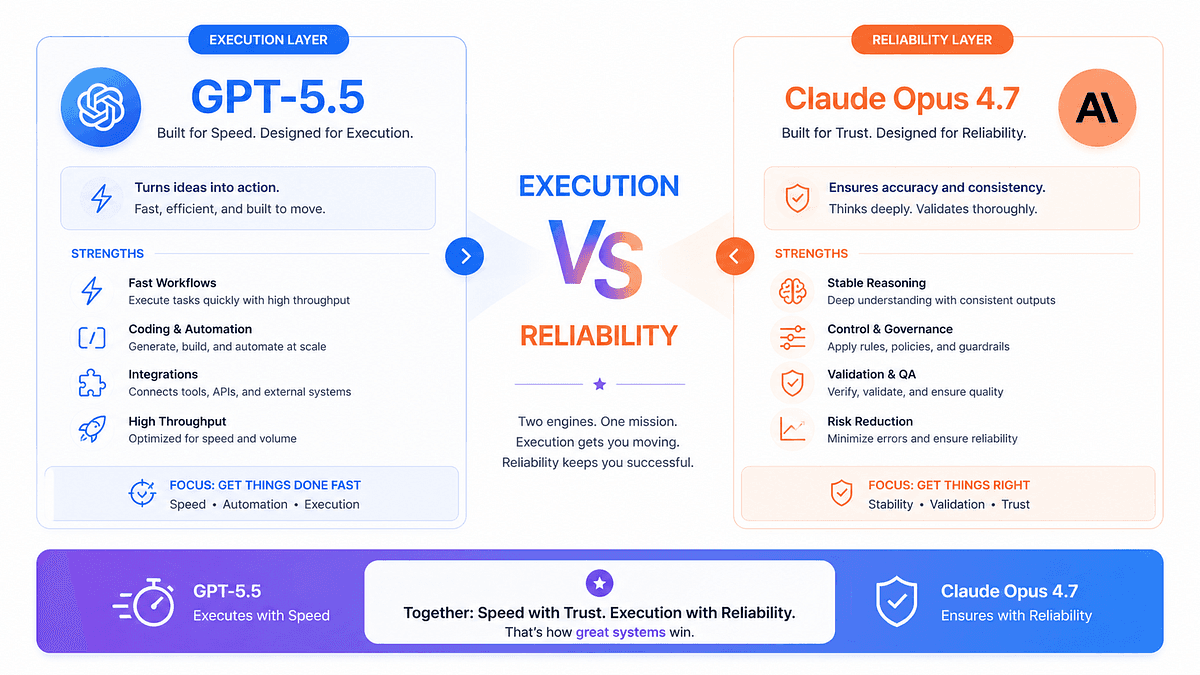
GPT-5.5 is the Operating Layer: Optimized for build speed, creative generation, and agentic execution.
Claude Opus 4.7 is the Reliability Engine: Optimized for safety, validation, and reasoning stability.
The Winner? They aren't competitors. The best strategy is a hybrid AI architecture where one executes and the other validates.
🎯 Introduction
When developers start asking about GPT-5.5 vs Claude Opus 4.7, they usually have one problem: they are trying to find "the smartest" AI.
But in a production environment, raw speed isn't the constraint. Hallucination rates and control stickiness are.
In real-world usage, relying on a single model for both execution and validation is a recipe for expensive production failures. The debate between GPT-5.5 vs Claude Opus 4.7 isn't about who wins a benchmark chart; it's about which layer fits your system architecture. One optimizes for volume; the other optimizes for truth.
🧠 Core Explanation
The confusion usually stems from treating Large Language Models (LLMs) as identical tools. But recent architectural shifts have created two distinct philosophies:
1. The OpenAI Approach (GPT-5.5): The Operating Layer
GPT-5.5 feels like an operating system. It doesn't just answer questions; it acts.
It aggregates context well.
It handles complex multi-step logic autonomously.
It changes state or code frequently.
It is engineered for velocity.
2. The Anthropic Approach (Claude Opus 4.7): The Control Layer
Claude Opus 4.7 feels like a governance board or a control layer.
It excels at editing and refining code without breaking functionality.
It has superior context retention and "groundedness."
It excels at chain-of-thought reasoning without hallucinations.
It is engineered for stability.
🔥 Contrarian Insight
Most engineering teams make the mistake of picking the model that scores highest on the MMLU (Massive Multitask Language Understanding) test.
Here's the catch:
The industry is shifting from "AGI" hype to "Agent Economics." You can have the smartest brain in the room (GPT-5.5), but if it lacks social safety and self-correction loops (Claude Opus 4.7), that brain will eventually crash your production server on a Friday afternoon.
Share This Bit
The leverage isn't in picking the winner; it's in picking the layer.
If you want to build a complex system, you don't want the smartest cop on the beat. You want a prosecutor who knows every case law, and a defense attorney who knows every loophole. They do the same job; they serve different masters.
🔍 Deep Dive: Architecture & Differences
To understand GPT-5.5 vs Claude Opus 4.7, you must analyze their optimization goals.
Execution vs. Validation Logic
Think of software development as a loop:
Drafting: Requires creative freedom and context bandwidth. Winner: GPT-5.5.
Parsing & Patching: Requires absolute precision and strict adherence to rules. Winner: Claude Opus 4.7.
In my experience, teams that force GPT-5.5 to do "validation" often see their latency triple and their error logs spike. Conversely, trying to get Claude Opus 4.7 to refactor a massive legacy module rapidly often frustrates developers due to slower token generation speeds.
Reasoning Stability
Claude Opus 4.7 appears to have improved "temperature" control. It doesn't "guess" an answer as often; it analyzes why it needs to generate an answer.
GPT-5.5 is excellent at "Chain of Thought" for solving puzzles but requires strong system prompts to reduce creative hallucinations.
Claude Opus 4.7 naturally minimizes nonsensical output, acting as a natural filter.
🏗️ System Design: The Multi-Agent Battle (The Practical Architecture)
This isn't just theoretical. This is how you should architect your production stack.
The "Handshake" Workflow
Instead of choosing one, you design a pipeline:
Agentic Agent (GPT-5.5):
Role: Explores the canvas. Generates the initial PRD (Product Requirements Document), writes the scaffold code, and crafts the API response text.
Risk: May suggest code that looks good but violates security policies.
Validator Node (Claude Opus 4.7):
Role: Connects to the repo. analyzes the new code introduced by step 1.
Action: If the code violates strict rules or has logic holes, Claude rejects the PR (Pull Request) and prompts GPT-5.5 to fix it.
Risk: None if handled correctly, or simply slightly higher latency.
Why this wins
This architecture solves the "Vibes-based Coding" problem where AI changes your libraries for no reason.
🧑💻 Practical Value: What Should You Do Now?
You don't need to wait for the release if you are building today. Here is the deployment strategy for teams:
Step 1: Audit Your "Failures"
Review your last 5 production incidents. Did you experience:
Logic Loops (The infinite loop)? -> You likely need Claude Opus 4.7 for the main logic.
Missing Features? -> You likely processed GPT-5.5 inputs too strictly.
Step 2: Implement a "Model Router"
Most APIs now allow model selection per call. Don't hardcode model="gpt-5.5".
Use { "intent": "creative", "model": "gpt-5.5" }
Use { "intent": "safety_check", "model": "claude-opus-4.7" }
Step 3: Rate Limit biases
If your application involves user-generated content moderation or financial safety, force the use of Claude Opus 4.7. Do not treat it as an optimization tool; treat it as a hardware safety standard.
⚔️ Comparison Matrix
Feature
GPT-5.5
Claude Opus 4.7
Primary Archetype
The Creator / Operator
The Guardian / Validator
Speed of Thought
Fast, agile,enerative
Slower, deliberate, analytical
Context Window
Massive (Expansive)
Deep (High retention)
Best Use Case
Agentic Workflow, Content Gen, Code Scaffolding
Code Review, Security Audit, Compliance Logic
Learning Curve
Low (just ask)
Higher (requires strict prompts)
Price (Approx)
Competitive
Premium/Smaller context efficiency
⚡ Key Takeaways
Stop comparing intelligence; compare utility. GPT-5.5 is better at doing; Claude Opus 4.7 is better at being right.
Hybridization is the future. The winning engineering teams are using GPT-5.5 to build and Claude Opus 4.7 to guard.
Control layer wins in scale. As apps get complex, hallucination cost goes up exponentially. You need a control layer.
Architectural fit matters. Pick the model that complements the workflow of your agent, not the one that looks the coolest.
The distinction between reasoning and acting will blur further. We will likely see fine-tuning on specific "summoners"—specialized versions of GPT-5.5 and Claude Opus that hard-code their behaviors. For now, however, GPT-5.5 vs Claude Opus 4.7 represents the fork in the road between a "smart toy" and a "professional tool."
❓ FAQ
Q: Which is faster to code with?
A: GPT-5.5 is generally more responsive and creative, making it faster for drafting new features.
Q: Does Claude Opus 4.7 struggle with complex logic?
A: Recently, yes, it has been managed to be on par with GPT-5.5's reasoning capabilities, which is exactly why we use it—to verify the logic of the faster, more creative model.
Q: Can I use both for free?
A: Typically, larger models like GPT-5.5 and Claude Opus 4.7 require paid tiers on major providers (like OpenAI or Anthropic due to compute costs).
Q: Is GPT-5.5 better for creative writing?
A: Generally, GPT-5.5 offers more diverse styles and faster generation, while Claude Opus 4.7 produces prose that is factually tighter and less prone to logical inconsistencies.
Q: Why is reliability more important than intelligence now?
A: Because we are moving from "chatting" to "autonomous execution." If an AI executes a task reliably 100 times a day, it earns its keep. If it executes a task smartly but crashes the server once, the ROI is negative.
🎯 Conclusion
The narrative around GPT-5.5 vs Claude Opus 4.7 often misses the forest for the trees. The battle isn't about who is smarter; it's about who plays which position.
GPT-5.5 powers execution. Claude Opus 4.7 ensures reliability.
If you want deeper insights into AI systems, multi-agent architectures, and building production-ready AI stacks, follow
CTA: Don't roll a single die when you can control the board. Build a stack.