Stop Blaming the LLM: Why Your AI Architecture is Actually Failing Risk Reviews
BitAI Team
April 29, 2026
5 min read
🚀 Quick Answer
Stop blaming the LLM when your AI architecture fails risk reviews in production. The root cause isn't your model's reasoning; it is almost always your retrieval strategy. Select the right architecture based on your data structure:
Use Vector RAG when documents are unstructured, short (under 50 pages), and fuzzy, and you prioritize low latency.
Use PageIndex when documents are long, structured, and regulated, and you require an auditable reasoning trail.
Hybridize only if your corpus contains both high-volumes of news and low-volumes of legal contracts.
🎯 Introduction
Stop blaming the LLM when your AI architecture fails risk reviews. The pattern I've seen across ninety-three production applications is consistent: teams pick a tool before solving a problem. In regulated environments, assuming meaning lives in the relationship between words (Vector RAG) fails when meaning lives in the structure (PageIndex). To fix your production systems, you must stop treating retrieval as a "nice-to-have" feature and start validating if your data requires "neighborhood search" or "structural reasoning."
🧠 Core Explanation: The Two Philosophies of Meaning
We are not just choosing a database; we are choosing a theory of meaning.
1. Vector RAG: Meaning Lives in Word Neighborhoods
Vector RAG assumes language is a dense map where similar concepts cluster together. It works by splitting documents into chunks (usually ~512 tokens), converting them into dense vectors, and retrieving neighbors based on cosine similarity.
Pros: Low latency (milliseconds), handles fuzzy queries well (e.g., "weather today"), scales to millions of docs.
Cons:Silent failures. It retrieves text that "sounds like" the answer but gets the semantic details wrong. It creates no audit trail.
2. PageIndex: Meaning Lives in Document Structure
PageIndex replaces embeddings with a hierarchical tree that mirrors the physical document (Tables of Contents, Section headers, Subsections).
Pros:High Recall on structured data. It finds the "Risk Factors" section even if the user asks about "Main dangers" and then navigates the tree.
Cons: Higher cost and latency. It requires sequential LLM calls to "walk" the tree.
🔥 Contrarian Insight
The industry is pushing embeddings harder, but the data is getting messier. I have watched otherwise excellent retrieval systems fail third-party audits because the team couldn't explain a specific passage was retrieved. A cosine score of 0.87 is not a defense in a regulatory hearing or a risk committee review. We treat similarity as a proxy for truth, but in regulated environments,
Share This Bit
why
proximity is not proof.
🔍 Deep Dive: The Architecture Gap
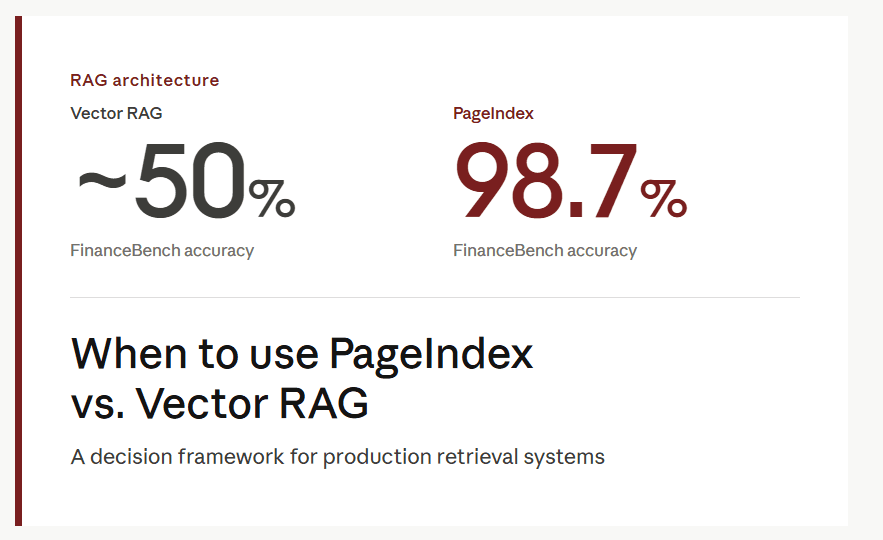
On FinanceBench, a benchmark for long financial filings:
Vector RAG: ~50% Accuracy.
PageIndex: 98.7% Accuracy (reported by VectifyAI).
This gap exists because Vector RAG struggles with "distributed" information. In a drug monograph or legal contract, the answer might be split across a Header, a Table, and a Footnote. Vector RAG retrieves one piece of that data and hallucinates the rest. PageIndex understands that to answer the question, the system must traverse the node graph to read the specific node containing the interaction table securely.
3. A Seven-Question Decision Framework
Before you write a single line of ingestion code, answer these seven questions.
Document Structure: Are your docs long (50+ pages) and are they highly structured (chunks with consistent headers)?
Cross-Section Reasoning: Does the answer require reading Chapter 2, then skipping to Chapter 5, and then Chapter 9?
Auditability: Is the output subject to auditors or regulator compliance? Can you defend the answer? (Vector similarity scores are not admissible; node paths are).
Vocabulary Ambiguity: Is there a risk of the user asking in one way ("risk factors") while the document uses another ("procurement traps")?
Throughput: Do you need to answer 1,000 queries per second, or 10 per minute?
Data Types: Is your data a mix of unstructured emails and structured contracts?
Hybrid Potential: Are you willing to pay the orchestration cost to combine both?
🏗️ System Design: Implementing PageIndex
If you determine your architecture requires PageIndex, your system design shifts from a "Map" to a "Tree."
Data Schema Concept:
Instead of storing chunks as flat tensors, store parent-child relationships.
Root Node: The full document.
Level 1: Main Sections (TOC).
Level 2: Sub-sections (Headers).
Ingestion Flow:
Layout Analysis: Use a form of HTML parsing or layout detection to identify headers.
Tree Construction: Build a JSON-LD structure representing the hierarchy.
Storage: Store the nodes in a database with pointers (neighboring parent/child pointers).
Query Runtime (Pseudo-Code):
def query_risk(document_tree, question):
# Step 1: Summarize Table of Contents
toc_summary = summarize_node(document_tree.toc)
relevant_section_id = choose_section_based_on_question(toc_summary, question)
# Step 2: Descend the tree (Sequential Retrieval)
current_node = document_tree.get_node(relevant_section_id)
context = ""
while current_node.has_children():
# Decide whether to go deeper into sub-sections
decision = is_sub_section_relevant(current_node.text, question)
if decision:
current_node = current_node.children[0] # Go deeper
else:
break
final_answer = construct_answer(current_node.text, question)
return final_answer, [relevant_section_id] # Trace is built-in
Note the difference: Vector RAG launches 10 parallel requests. PageIndex launches 3 sequential requests. This chain of calls is the only thing that guarantees you know exactly where the answer came from.
⚔️ Comparison: Vector RAG vs. PageIndex
Feature
Vector RAG
PageIndex
Core Mechanism
Dense Embeddings + Cosine Similarity
Hierarchy Traversal + LLM Reasoning
Document Suitability
Short, Unstructured, High Volume
Long, Structured, Low Volume
Latency
Low (ms)
Moderate (seconds)
Cost
Low
Higher (more tokens parsed)
Audit Trail
Weak (Statistical score only)
Strong (Node path reference)
Failure Mode
Silent Hallucination (Retrieval mismatch)
Low Precision (Tree too deep)
🧑💻 Practical Value: Which to Build?
The Decision Matrix
Build PageIndex if: You are in FinTech, LegalTech, or Pharma. Your documents are PDFs with clear chapters. Action: Set up a layout analysis pipeline for your PDF ingestion.
Stick with Vector RAG if: You are building a consumer chatbot, FAQ bot, or news aggregator. Action: Focus on optimizing your chunk size and embedding model to reduce hallucinations.
Build a Router if: You have a mixed corpus. Action: Use a lightweight classifier (NLI model) to route the query to the appropriate backend before it hits the expensive reasoning loop.
Common Pitfalls
Chunking Inertia: Don't force PageIndex logic onto 1MB of raw text scraped from Reddit. You will incur massive costs for zero gain.
Ignoring the "Footnote" Problem: The original prompt highlights a critical failure mode. If your answer is in a footnote (often low-ranked in embeddings), PageIndex remains superior.
⚡ Key Takeaways
Architecture is Governance first: In regulated industries, retrieval isn't an engineering edge case; it's a trust layer.
Meaning is Structural or Neighborhoodal: You cannot retrofit structure onto noise-nature text.
Vector RAG is the default trap: It is the "cheap" answer that costs you money in audits and legal disputes.
Hybrid is the truth: Most production systems need a routing layer.
❓ FAQ
Q: Can I use both Vector DB and PageIndex?
A: Yes. Use Vector RAG to find which documents might have the answer, and use PageIndex to find the exact clause within that document.
Q: Is PageIndex too slow for production?
A: Only if your query volume is massive (millions/day). For internal enterprise systems handling thousands of queries, the latency is acceptable.
Q: How do I handle messy documents?
A: PageIndex struggles with genuinely messy data. If your headers are inconsistent, Vector RAG is likely the better tool, or you need a pre-processing step to "standardize" the document PDF.
The next time an AI fails a "risk review," do not point to the hallucination. Look at your retrieval architecture. If your documents rely on structure rather than proximity, you are likely using the wrong system. Stop blaming the model, and start blaming the architecture.