Technology
The Best Agentic RAG Architectures Every Developer Must Know
🚀 Quick Answer
- Old RAG is dead: Static retrieval pipelines are no longer sufficient for modern AI agents that require autonomous decision-making.
- Hybrid Retrieval: Combining vector search with keyword (BM25) and Reciprocal Rank Fusion (RRF) solves the precision vs. recall problem.
- DSPy replaces prompting: Treat prompts as code and let an optimizer find the best logic, often doubling system performance.
- LangGraph enables loops: Agents need complex control flows—state machines for re-verification and self-correction.
- Corrective RAG (CRAG): An LLM-grade workflow that checks retrieved documents and falls back to web search if confidence is low.
🎯 Introduction
Most RAG tutorials are still teaching patterns from 2022. They show you how to ingest a PDF and query a vector database. But if you’re building production-level AI agents today, that architecture will fail you. The industry has shifted from RAG pipelines to Agentic RAG architectures.
In a traditional system, retrieval is a fixed step. In the new paradigm, retrieval is an autonomous agent that decides when to search, how to search, and if to trust the results. If you ignore this shift, your AI agents will hallucinate or provide incorrect answers.
Here, we break down the advanced RAG architectures leading the industry right now, complete with system design insights and code that you can run.
🧠 Core Explanation
The fundamental problem with legacy RAG is compounding uncertainty. You fetch a set of documents, hope they are relevant, and ask the LLM to generate an answer. If the information in the top 3 documents is noisy, the LLM hallucinates.
Modern Agentic RAG architectures attack this in three ways:
- Precision: We no longer just search; we search smarter using Hybrid retrieval and Reranking.
- Auditability: We don't trust the LLM blindly. We use "graders" (LLMs) to grade their own work.
- Adaptability: We use optimizer frameworks like DSPy to tune the logic, not just the prompt.
Most AI teams are moving away from hand-crafted prompts and toward practice-based engineering. This is how we move from chatbots to truly useful agents.
🔥 Contrarian Insight
"Your vector database alone is not an AI engineer."
I cannot stress this enough. A vector database is just storage. If you think dumping 10,000 documents into Pinecone or Qdrant and configuring a similarity threshold makes your system "smart," you are going to ship a broken product. The "architecture" lives in the orchestration layer (LangGraph/DSPy) and the evaluation layer (RAGAS), not in the database config.
🔍 Deep Dive: The 5 Architectures
If you are designing a system for 2024 and beyond, you need to stack these. None of these work in isolation. They are modular patterns.
1. Hybrid Retrieval & Reciprocal Rank Fusion (RRF)
The fix for irrelevant context.
Pure vector search is great for semantic understanding (e.g., "dog" matches "puppy"), but it fails at exact matches (e.g., specific legal code numbers or precise timestamps). Pure keyword search (BM25) fails at synonyms.
The Architecture:
- Run a Vector Search.
- Run a BM25 Keyword Search in parallel.
- Merge results using Reciprocal Rank Fusion (RRF).
- (Optional but Recommended) Pass the merged context to a Cross-Encoder Re-ranker for final scoring.
The Logic: $$score_{d} = \frac{1}{k + rank_{vector}(d)} + \frac{1}{k + rank_{keyword}(d)}$$
Hint: Most major Vector DBs (Redis, Qdrant, Pinecone) support Hybrid Search natively now. If yours doesn't, it is time to switch.
2. Corrective RAG (CRAG) - The State Machine
The fix for hallucinations.
CRAG treats document retrieval as a test. We grade the retrieved documents for relevance:
- High Confidence: The LLM generates the answer based on documents.
- Low Confidence: The system treats the documents as "Corrupted" or "Irrelevant" and attempts to modify the query (internal rewrite) or falls back to Web Search.
This is usually implemented using a library like LangGraph to handle the state transitions.
3. DSPy: Programming Agents, Not Prompting
The fix for "Good Enough" performance.
Most engineers spend 80% of their time writing prompts. DSPy (from Stanford NLP) flips this. You don't write prompts; you write signatures and modules.
How it works:
- Define the Logic:
answer(question, context)->answer - Choose the Modules:
ChainOfThought,ReAct,DetermineAnswerGorithm. - DSPy Optimizer: You don't pick the words. The optimizer finds the best few-shot examples and dynamically builds the prompt for you.
Real-World Performance: Teams report jumping from 42% to 61% in Semantic F1 scores with zero manual prompt tuning.
4. LightRAG (Graph RAG)
The fix for multi-hop reasoning.
Vector search is linear (Find similar chunks). Knowledge Graphs (Graph RAG) connect entities. When a user asks, "What are the economic impacts of the climate policies mentioned in these documents?", a Graph can traverse "Policy" -> "Economy" -> "Impact".
The Challenge: Full Graph RAG requires expensive LLM calls to extract triples and build a graph. LightRAG Solution: Published at EMNLP, it builds a lightweight graph on the fly, performs dual-level retrieval (specific entity vs. thematic summary), and is significantly faster and cheaper.
5. MCP (Model Context Protocol)
The USB-C of AI Agents.
MCP is becoming the standard for connecting AI agents to tools. It allows an agent to "contract tools" rather than hardcoding API keys.
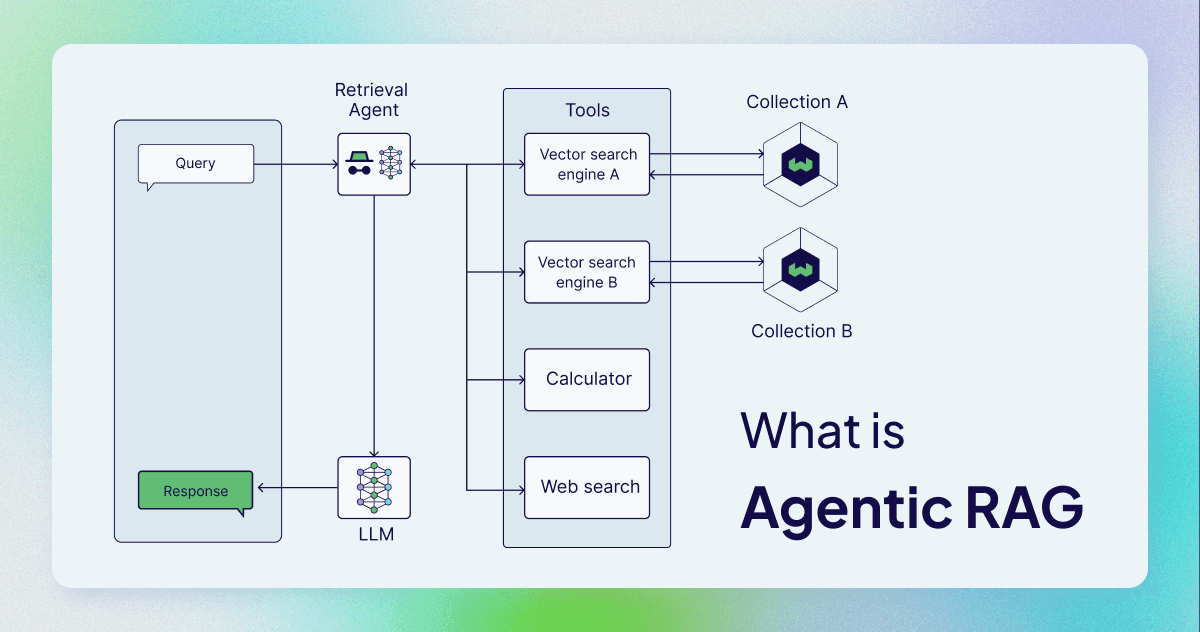
In the context of RAG, MCP allows the agent to discover when to use a knowledge base (RAG tool) vs. when to use a calculator, simply by inspecting the available tools.
🏗️ System Design for Agentic RAG
Deploying these architectures requires a scalable backend. Here is the typical stack for a modern Agentic RAG system:
1. Orchestration Engine
- LangChain / LlamaIndex: Good for quick setup.
- LangGraph: Superior choice for complex agent loops (memory, human-in-the-loop).
- DSPy: For optimizing the agent's internal logic/LLM calls.
2. Retrieval Layer (The "DB")
- Vector Store: Redis, Qdrant, Weaviate.
- Hybrid Feature: Enable dense + sparse search.
- Reranking: Cross-encoder model (Cohere, BGE).
3. Evaluation (CI/CD)
- RAGAS: Measures Truthfulness, Context Precision, and Relevancy.
- Semantic Cache (RedisVL): Crucial for cost/bandwidth. If
query(vector) matchesrecent_query, return the cached response.
🧑💻 Practical Value: Implementation
Here is how to implement Hybrid Search + Semantic Cache in a real environment.
Step 1: Semantic Caching (Stop burning money)
You don't need a complex system for this. Check if the query appears in the last 100 requests.
# Python Implementation Concept
from redis import Redis
from sentence_transformers import SentenceTransformer
client = Redis(host='localhost', port=6379, db=0)
encoder = SentenceTransformer('all-minilm-l6-v2')
query_embedding = encoder.encode("What is the API status?").tolist()
# Search for similar queries in Redis
results = client.knnsearch("queries", query_embedding, M=1, k=1, RETURN_FIELDS=['response', 'created_at'])
if results:
print(f"CACHED RESPONSE: {results[0]['response']}")
else:
# Standard RAG pipeline here...
answer = rag_pipeline.execute(query)
# Store result
client.kvset(f"resp:{hash(query)}", {"response": answer, "vec": query_embedding})
Step 2: Evaluation Metrics
Do not ship without monitoring.
# Using RAGAS for automated testing
from ragas.metrics import faithfulness, context_relevancy
from ragas importevaluate
result = evaluate([test_dataset], metrics=[faithfulness, context_relevancy])
print(result)
⚔️ Comparison: RAG Pipeline vs. Agentic RAG
| Feature | Old Architecture (Pipeline) | Modern Architecture (Agentic) |
|---|---|---|
| Flow | Linear: Retrieve -> Generate | Loops: Retrieve -> Grade -> Iterate |
| Diversity | Single search strategy | Strategies defined by agent state |
| Knowledge | Static Knowledge Base | Dynamic (Retrieval + Web + Tools) |
| Maintenance | Hand-crafted prompts | Optimizer-driven DSPy logic |
| Cost | Higher (Always runs) | Lower (Self-correction avoids wasted tokens) |
⚡ Key Takeaways
- Adaptive RAG is non-negotiable. Your agent needs to know when to "give up" on its own knowledge base and switch to web search (CRAG).
- DSPy is the future of prompt engineering. Stop guessing good prompts; let the optimizer learn the best few-shot examples.
- Graphs are back. For complex questions requiring multi-hop reasoning, LightRAG is superior to pure vector search.
- Hybrid is the standard. Use both Vector and Keyword search (RRF) to ensure precision.
- MCP is the connector. Use it to make your agent flexible and tool-agnostic.
🔗 Related Topics
- How to Optimize LLM Latency for 2024
- Vector Database vs Knowledge Graph: The Definitive Deep Dive
- Building AI Agents with LangGraph (Tutorial)
- Inside the DSPy Framework: Stanford's Optimization Breakthrough
🔮 Future Scope
The next step beyond these architectures is AutoAgents. Currently, we define the architecture (Hybrid + RAG + MCP). In the future, the system will observe user behavior, learn which tools are most effective for specific tasks, and rewrite its own architecture dynamically. We are moving from "Describing the agent" to "Teaching the agent."
❓ FAQ
Q: Is standard RAG (retrieval-only) completely dead? A: No, it is a sub-component. Base RAG is fine for simple Q&A, but if you need the "Agentic" capabilities (web searches, self-correction, tool use), you must upgrade.
Q: Which vector database should I use for Hybrid Search? A: Qdrant and Redis have the most mature Hybrid Search capabilities that don't require complex multi-database setups.
Q: Do I need to learn DSPy? A: Only if prompt tuning is a bottleneck for you. If your team prefers manual control over the prompts, stick to LangChain, but be aware that generic prompts often plateau in performance.
🎯 Conclusion
The era of "Feed a raw PDF to a model and hope for the best" is over. To build AI systems that developers can rely on, you must implement Agentic RAG architectures.
Start by layering Hybrid Retrieval on top of your current Vector DB. Immediately add a Semantic Cache to save budget. Then, experiment with DSPy to see if your prompts can be optimized by code.
The tools are open source. The papers are public. The stack is ready. Are you?
Share This Bit