AIAI AgentsClaudeClaude Code
The Blind Spot: How OpenWolf’s Second Brain Architecture Cuts Token Usage by 5x
🌩️ The Blind Spot: How OpenWolf’s Second Brain Architecture Cuts Token Usage by 5x
TL;DR: Claude Code, currently, operates like a forensic analyst who refuses to look at the case file you already have open. It is pragmatically "blind"—unable to distinguish a 50-token configuration string from a sprawling 2,000-line architecture module, and it often re-reads the same document three to four times in a single sitting. OpenWolf is an innovative, open-source middleware layer running locally that inserts a "second brain" between your workflow and Claude Code. By intercepting file interactions via six Node.js hooks, it generates project indexes, cross-session memory logs, and token-aware filters, resulting in an industry-leading 65.8% reduction in token consumption across diverse codebases.
Have you ever watched an AI pair programmer engineer a critical feature, only to observe it backtracking to reread a file it had just parsed a few moments ago? It feels inefficient. It feels like watching a mathematician re-derive the Pythagorean theorem every time they need to calculate a square root. The friction is real, and it is expensive.
Claude Code represents a paradigm shift in software development—moving from simple code completion to autonomous, multi-step reasoning. Yet, it suffers from a fundamental architectural limitation: it lacks persistent, token-aware memory of your local environment. It does not know your codebase "by heart" until it has read it. This isn't a bug; it is a property of how Large Language Models (LLMs) process information in a stateless or semi-stateless environment. However, this "blindness" creates a phenomenon known in AI engineering as Token Bleed, where context consumption spirals out of control, inflating API costs and destroying efficiency.
In this deep-dive exploration, we will dismantle the architecture of OpenWolf, an open-source middleware layer that solves this specific problem with surgical precision. We will look at how a collection of local Node.js hook scripts and a .wolf/ directory transforms Claude from a reactive tool into a proactive expert.
💡 The "Why Now": Context Saturation and the Economics of AI
We are on the precipice of a new era in tech called Autonomous Engineering, but the fuel for this engine—tokens—is finite and expensive. Why has the concept of "Second Brains" for AI become critical now?
📉 The Context Window Ceiling
The immediate pressure comes from the hard constraints of the context window. As developers push for agentic workflows—complex, multi-step coding tasks that span thousands of files—the limit is hit quickly. When Claude attempts to perform a top-down architectural analysis, it must ingest the function prototypes, file structures, and configuration schemas. If it lacks this pre-knowledge, it defaults to a bottom-up approach, frequently opening files it doesn't need yet or re-opening files it looked at ten minutes ago.
💸 The Token Economy
Beyond theoretical context constraints lies the brutal economic reality. While hourly developer rates climb, the cost of data "ingestion" via APIs does not scale favorably for large-scale file operations. A project with 1,000 files isn't a 1,000-token task; it is a potential 500,000-token nightmare if AI agents treat each file as a fresh, unknown entity.
🤖 The Agent Evolution
The shift from "Augmentation" to "Autonomy" means we can no longer hand-hold the AI through a workflow. We are deploying digital workers who must navigate our messy codebases. To do this reliably without supervision, these agents need memory. OpenWolf is not just a tool; it is the foundational infrastructure required to train AI agents on proprietary data economically.
🏗️ Architecture of a Second Brain
The solution to this redundancy is not to make Claude smarter natively; it is to level the informational playing field in its favor. OpenWolf acts as a proxy. It sits invisibly in the middle of your terminal, intercepting your communication with Claude Code. It is a "software mediator." It intercepts every request to open a file, every write operation, and every session event.
When you run a command like openwolf init, the system doesn't just install a script; it seeds a new ecology within your project. It creates a .wolf/ directory—a hidden, centralized repository of intelligence.
🧩 The .wolf/ Ecosystem
The .wolf/ directory is the heart of the architecture. It holds the state of the project, stripping the constant need for out-of-band file reading. Let’s explore the critical artifacts that make this magic happen.
📋 anatomy.md: The Project Index
This is the file that eliminates 80% of the noise. It is an auto-generated, project-wide map that functions like a detailed table of contents. Unlike a standard standard ls -la output, anatomy.md contains human-readable descriptions and rough token counts.
- Semantic Clarity: It tells Claude: "This file is
auth.ts– it handles JWT validation." This allows Claude to make decisions before hitting the "Read" button. Does the AI need the code to know thatauth.tscontains authentication logic? Probably not. Knowing the description is often enough. This "skip" mechanism saves massive amounts of context. - Estimation Accuracy: By tagging files with token counts (e.g.,
(~340 tok)), OpenWolf provides the LLM with a budget. Claude can now calculate: "I need to understand the middleware, but this is only 340 tokens. The Dashboard file is 1,200 tokens. I might hold off on the Dashboard until I'm ready."
🧠 cerebrum.md: The Learning Memory
This represents the most significant paradigm shift in human-AI collaboration. This file acts as a project-specific set of rules and a persistent memory of your corrections.
- Convention Injection: If your team has strict conventions—such as "All API responses must be wrapped in
{ data, error, meta }"—OpenWolf encapsulates this incerebrum.md. - The Feedback Loop: If you were working with an older version of Claude and the AI wrote code using
varinstead ofconst, you would typically have to rewrite it manually. With OpenWolf, that correction is logged. The next time you run Claude, thecerebrum.mdfile is loaded. The pre-write hooks detect the impending violation. - Compliance Reality: It is crucial to understand that this compliance is high—approximately 85–90%—but not absolute. The AI still retains autonomy. This is better than 100% rigidity, which can break the AI's reasoning. It acts as a moderator, not a dictator.
🗂️ memory.md: The Session Log
Think of memory.md as the "Black Box" flight recorder for Claude Code. It is a chronological log of the AI's actions within a specific session.
- Redundancy Detection: If the AI reads
src/utils/db.tsand logs it tomemory.md, the pre-read hook checks this log upon the next request. If the file hasn't changed, the AI is slapped with a warning: "You already read this file 12 minutes ago." - Audit Trails: For complex debugging, this log is invaluable. It tells you definitively in what order Claude approached the problem. This aids in diagnosing why a fix failed or why an agent hallucinated a solution.
🩺 buglog.json: The Fix Memory
True institutional knowledge is often lost to developer memory. The AI doesn't know that "Error 500 on /users often happens when the DB connection times out."
buglog.json solves this. When a specific bug signature is detected, it is logged with an attached fix.
- Self-Correction: When the error signature appears again in a new session,
pre-readhooks for debugging tools can scan this JSON file. The AI doesn't have to rediscover the fix; the fix is served directly.
💰 token-ledger.json: The Receipt
This file provides proof of efficiency. Every session ends with a granular breakdown: reads, writes, anatomy hits, and blocked redundant operations. It allows you to prove that OpenWolf is working and to visualize the growth of efficiency over time.
🔓 Unpacking the Six Hooks: Enforcement at the Core
The .wolf/ directory creates the state, but the Hooks create the action. These are the microscopic, invisible agents running in Node.js that bridge the gap between your file system and Claude Code’s command-line interface.
⚡ Hook 1: session-start.js (SessionStart)
This is the initialization ceremony. Every time you fire up a new Claude session, this script wakes up:
- It clears the mental heap for the current session.
- It loads
anatomy.mdinto memory—a map of the entire project. - It loads
cerebrum.md—the team's 2-week history of conventions. - It initializes
memory.md(creates a new timeline for the current session).
This wipes the slate clean but simultaneously hands Claude a cheat sheet.
🔒 Hook 2: pre-read.js (PreToolUse, Read)
This is the superstar of the operation. It fires immediately before Claude attempts to open any file.
- Anatomy Injection: It injects the description from
anatomy.mdinto Claude's stream.- Current Claude: "I need to check the DB connection settings."
- With Hook: "I need to check the DB connection settings. Based on the project index,
db.tsis a utility file (~120 tok). Is the description sufficient, or do I need the code?"
- Redundancy Check: It checks
memory.md.- Claude opens
config.ts. - Hook says: "You opened
config.tsat 10:04 AM 15 minutes ago. The hook also confirmsconfig.tsis tiny (50 tok). Do you really need to read it again, or can the previous 50 tokens suffice?"
- Claude opens
Without this, Context Compaction kicks in, deleting older history to make room.
🖊️ Hook 3: pre-write.js (PreToolUse, Write)
This acts as the conscience.
- It takes the code block Claude intends to write.
- It scans
cerebrum.mdfor "Do-Not-Repeat" or convention violations. - If Claude attempts to use
varor calls a non-existent API method, the hook fires a warning message back to Claude in its chat stream before the write happens.
📊 Hook 4: post-read.js (PostToolUse, Read)
This is the receipt printer. It fires after the file is read. It calculates the token count of the content just ingested (approximately one character equals 0.25 tokens). This data is strictly for internal tracking to power the token-ledger.
🔄 Hook 5: post-write.js (PostToolUse, Write)
This is the maintenance crew. It fires after code is saved. It has two jobs:
- Anatomy Update: If the code type or structure of
auth.tschanges,anatomy.mdis updated with a new description; if the file grew to 500 lines, its token estimate is updated to(~500 tok). The index must stay accurate. - Memory Append: The write action is appended to
memory.mdas an event, preserving the timeline.
⏹️ Hook 6: stop.js (Stop)
The final curtain call. When the session ends, stop.js consolidates data. It closes the memory.md session, writes the daily aggregates to token-ledger.json, and shuts down the internal daemon process, saving the state for the next接班人.
📊 Unmasking the Redundancy Data
Dr. Farhan, the creator of OpenWolf, didn't just hypothesize; he tracked data. The results are staggering and validate the theoretical architecture above.
🕵️ The 132 Session Experiment
Dr. Farhan ran OpenWolf on 20 different projects, tracking 132 collaborative sessions with Claude Code.
The Signal: He found that Claude Code has no spatial awareness of the files it opens within a single session. It treats each File.read() command like a fresh exploration.
The Shocking Statistic: 71% of all file reads in these sessions were files that Claude had already opened in that same session.
- Scenario: Claude is building a feature. It reads
app.ts(context injected). Later, it needs a small function. It re-readsapp.tsbecause it forgot the specific line number or context. - Result: That
app.tsreading wasn't necessary because the first one was still valid context.
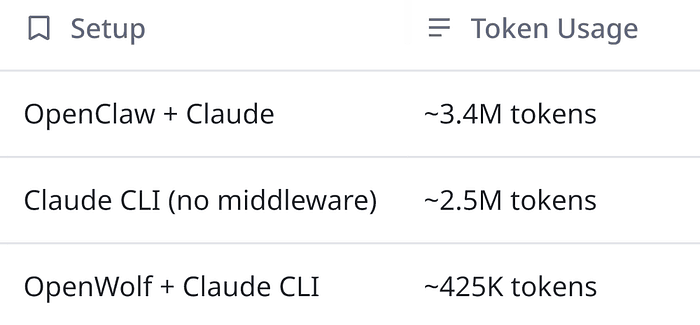
The Economic Comparison: The reduction in token usage is the metric that keeps architects awake at night.
- Without OpenWolf (Baseline):
- Large Project Session: ~1,500,000 tokens.
- With OpenWolf (Average):
- Large Project Session: ~300,000 tokens.
📈 The Reduction Math: That is an average reduction of 65.8% across all projects. On one large enterprise project, the reduction was even more dramatic, hitting nearly 80%.
The Insight: The savings aren't coming from better coding; they are coming from conservation. By preventing redundant reads and leveraging anatomy previews, OpenWolf conserves the most precious resource in the AI age: Context Space.
🚀 Deployment & Operational Dynamics
The beauty of OpenWolf lies in its deployment simplicity. You do not need to rewrite your CI/CD pipelines, npm scripts, or entry points. You do not need a specialized IDE.
⚙️ Installation & One-Click Setup
The barrier to entry is near zero.
npm install -g openwolf
This installs the system globally. From there, it's project-local magic.
cd your-project
openwolf init
This one command triggers a cascade of initialization:
- The Grid: It creates the
.wolf/directory with its specific ecosystem files. - The Hooks: It registers six Node.js hooks into the Claude Code lifecycle events (
PreToolUse,PostToolUse,SessionStart,Stop). - The Configuration: It updates your
CLAUDE.mdproject instructions. - The Scan: It performs an "Anatomy Scan," indexing your entire repo in seconds.
- The Daemon: It starts a
pm2background process to handle asynchronous tasks like memory consolidation.
🛡️ The Daemon Pattern
The use of pm2 is a crucial technical detail. Claude Code is often run ad-hoc. A process needs to stay running in the background to capture the state, save the ledger, and manage the memories. The daemon ensures that the file modifications (post-write) are tracked even if you close your terminal and the actual Claude Code session has paused.
🛡️ Privacy & Security Implications
Crucially, everything runs on your machine. There are no network requests.
- The Data Policy: Your
anatomy.md,cerebrum.md, and code files never leave your local filesystem. Theanatomymapping is local. - The Ecosystem: While optional, the scheduled AI tasks for anatomy rescans use your existing Claude setup. If you authorize outgoing requests to Claude, they go through your proxy settings, not OpenWolf's servers.
⚠️ Critical Trade-offs and Best Practices
While OpenWolf is a powerful tool, operating at the median layer between the developer and the AI requires awareness. Like any middleware, it introduces complexity you must manage.
Don't ignore the "Failure" mode:
The compliance rate is 85–90%, not 100%. Since cerebrum.md is just text instructions that the AI reads, it is possible for the AI to ignore them. This makes our AI coding partner a "wilder child" at times.
Best Practice: Reviewing cerebrum.md:
Don't set it and forget it. It is a living document. Review the "Do Not Repeat" section regularly. If you catch the AI making a massive convention violation, edit cerebrum.md manually (or yell at it through the terminal), and it will eventually learn and correct its behavior.
Expert Tip:
Don't fight the Indexing Time. When you run
init, it might take 10–15 seconds to scan a massive 5,000 file project. This is the price of preventing the future 500,000-token waste. View this 15 seconds as insurance against the next month of context leakage.
🔑 Telegrams from the Void: Key Takeaways
- 🩸 The Leak: Claude Code suffers from high redundancy, reading the same files multiple times in a session. This creates massive "Token Bleed."
- 🛡️ The Middleware: OpenWolf acts as a local proxy, intercepting file reads and writes to inject metadata and check history.
- 🧠 Memory Layers: It creates a
.wolf/directory that provides three critical layers: Project Indexing (anatomy.md), Learning Memory (cerebrum.md), and Session Logs (memory.md). - 🧮 The Savings: Data from 132 sessions shows a remarkable 65.8% average reduction in token usage, with specific high-traffic projects seeing up to 80% reduction.
- 🚫 The Rules: It acts as a compliance agent, warning the AI against violating conventions (like using
varor incorrect API shapes) before code is written. - 🔒 Privacy: All operations are local; no code leaves your machine, making it a secure solution for proprietary codebases.
🔮 The Roadmap to Intelligent Agents
Looking ahead, the trajectory of AI engineering points toward autonomous agents that can live and work within your codebase. OpenWolf is the foundational layer that makes this economically viable.
🧠 Multi-Agent Orchestration
Currently, OpenWolf works with a single "agent" (Claude Code). However, in the next 12 months, we will likely see middleware designed to bridge gaps between independent agents. One agent (chatting on Slack) might log a bug to buglog.json, and another agent (the coder) will resolve it. A unified anatomy.md ensures they are operating against the same facts.
🔗 Universal Context Indexing
We are likely to see the .wolf/ standard gain traction. It provides a "universal interface" for project understanding. Instead of every LLM product (Cursor, Windsurf, GitHub Copilot, Cline) requiring custom plugins to understand your code, they could all tap into a shared .wolf/ index.
⚖️ Adaptive Token Estimation
The current token estimation is heuristic (based on string length). Future versions of this middleware will likely integrate with the LLMs themselves to perform "empirical" reading—reading a small snippet of the file first, estimating its true size, and calculating context consumption with pixel-perfect accuracy.
❓ Frequently Asked Questions (FAQ)
🤖 How does OpenWolf prevent Claude from re-reading files?
OpenWolf operates on the principle that the AI's source of truth is the conversation history and the local file system. However, because Claude has no persistent memory, it re-explores files based on prompts. The pre-read.js hook checks a local session log (memory.md). If a file was read in the last session and no writes have occurred to it that would invalidate that context, the hook injects a warning message into Claude's interface: "You already read this file. Is it necessary to re-read?" This causes the AI to stop and decide if the data is still valid.
🌐 Is OpenWolf secure? Does it send my code to a server?
No. OpenWolf is entirely local. It is a collection of Node.js scripts that runs directly on your machine. It has no network requests, no external API calls, and no cloud dependencies. The project files (.wolf/) remain on your disk. The only optional AI features—scheduled anatomy rescans or deep Diffs—use your existing Claude API credentials, meaning data only leaves your machine if you explicitly authorized it for analysis.
📊 Can OpenWolf work with other AI coding assistants besides Claude Code?
The implementation described here (Hooks for Claude Code) is specifically tailored to the lifecycle events supported by the Claude CLI and API bridge. However, the concept of a "Second Brain" middleware is agnostic. You could theoretically build middleware that intercepts the _code_block stream from other tools (like Cursor or Copilot), inject metadata, and warn against redundancies, though the specific hook trigger points (File.write triggers vs. toggle events) differ by tool.
⚙️ Will OpenWolf slow down my development workflow?
In practice, the latency is negligible. The hooks run as synchronous file I/O within the npm scripts. The "scan" time happens once during initialization. The "blocking" time during file reads is less than a millisecond—the difference is imperceptible to a human. The time gain comes from the AI requiring fewer completions and revises because it has the necessary context in memory, resulting in a net speed increase.
🎬 Conclusion
The frustration of watching a powerful AI slowly unfold the same code file repeatedly is a symptom of a deeper architectural gap: the mismatch between our structured codebases and the LLM's stateless nature. OpenWolf does not merely optimize prompts; it aligns the tool with the environment. By building a "Second Brain" on our own machines—one that remembers, indexes, and conserves context—we have solved the cost of intelligence. We have stopped shedding tokens and started preserving them.
If you are building systems at scale, relying on the raw throughput of LLMs without architectural optimization is a mistake. Middleware is not a luxury; it is the framework of the AI-native web. To explore more on BitAI, dive into our comprehensive analysis of agent orchestration.
Share This Bit