AIAI AgentsAI AssistantChatgptClaudePrompt
Why Your AI Outputs Feel Hollow: The Truth About AI Prompting and Output Quality
We often blame the technology when our AI prompting needs improvement, but the real culprit is usually the input quality. To master effective AI prompting, one must understand that Large Language Models (LLMs) don't "think"—they predict. When your outputs feel hollow, grammatically correct but conceptually empty, you are suffering from the Average Output Trap. In this guide, we will break down the mechanics of lazy queries and introduce the GCIPO framework to permanently fix your workflow.
🚀 Quick Answer
Here are the three specific failure modes causing your AI outputs to be "hollow" and the single most effective framework to fix them:
- Semantic Ambiguity: If your terms have multiple meanings, the AI picks the most common one (usually the wrong one for your context).
- The Hallucination Loop: To meet your constraints, the model fabricates data rather than stating it doesn't know.
- Contextual Drift: In long threads, the model forgets tone, format, and regulatory standards defined in the first prompt.
- The Solution: Use the GCIPO Framework (Goal, Context, Inputs, Constraints, Output) to structure your prompts like engineering specs.
🎯 Introduction
After spending ten minutes reading an AI-generated report, it’s easy to feel frustrated. The text is clean. The structure is perfect. But it feels meaningless—like parroting a summary of a summary.
You’re not bad at AI. The tool isn't broken. You are operating in the "Average Output Trap."
The average AI response navigates toward the statistically most probable path. If you ask it vaguely, it becomes an average of the internet's average advice. If you want a professional-grade result, you must stop treating the AI like a creative partner and start treating it like a precision engine—a logic engine that requires precise coordinates to function.
🧠 Core Explanation
To fix your prompting strategies, we must first understand what the Large Language Model (LLM) actually is.
An LLM is a probabilistic text predictor. When you hit "send," the model isn't internalizing your request, formulating an opinion, and then writing a response. It is performing a search in its vast memory space for the most statistically likely sequence of tokens to follow your input.
Thus, input quality is the defining variable of output quality.
If you treat LLMs as search engines, you get parsable documents. If you treat them as logic engines or auditors, you get code, regulations, and automated quality control. The split between "hollow" and "high-value" output usually happens not because of the model version (GPT-4 vs Claude 3), but because one user structured their query for a creative assistant, while the other structured theirs for a professional specialist.
🔥 Contrarian Insight
"Giving AI maximum freedom produces maximum hallucinations, not maximum creativity."
Most new users believe they get better results by saying: "I'm not sure, just write something."
In reality, throwing a wide net, hoping the AI catches the right fish, destroys precision. The AI is forced to fabricate details to fill the gaps. To get high-value AI outputs, you must actively restrict the search space. By boxing the AI into specific constraints, persona details, and output formats, you force it to use its specialist knowledge rather than its "generalist" averaging mechanism.
🔍 Deep Dive: The Failure Modes & The Framework
The Three Mechanical Failure Modes
- Semantic Ambiguity: Using a word with multiple meanings causes the model to pick the least specific, highest-frequency definition.
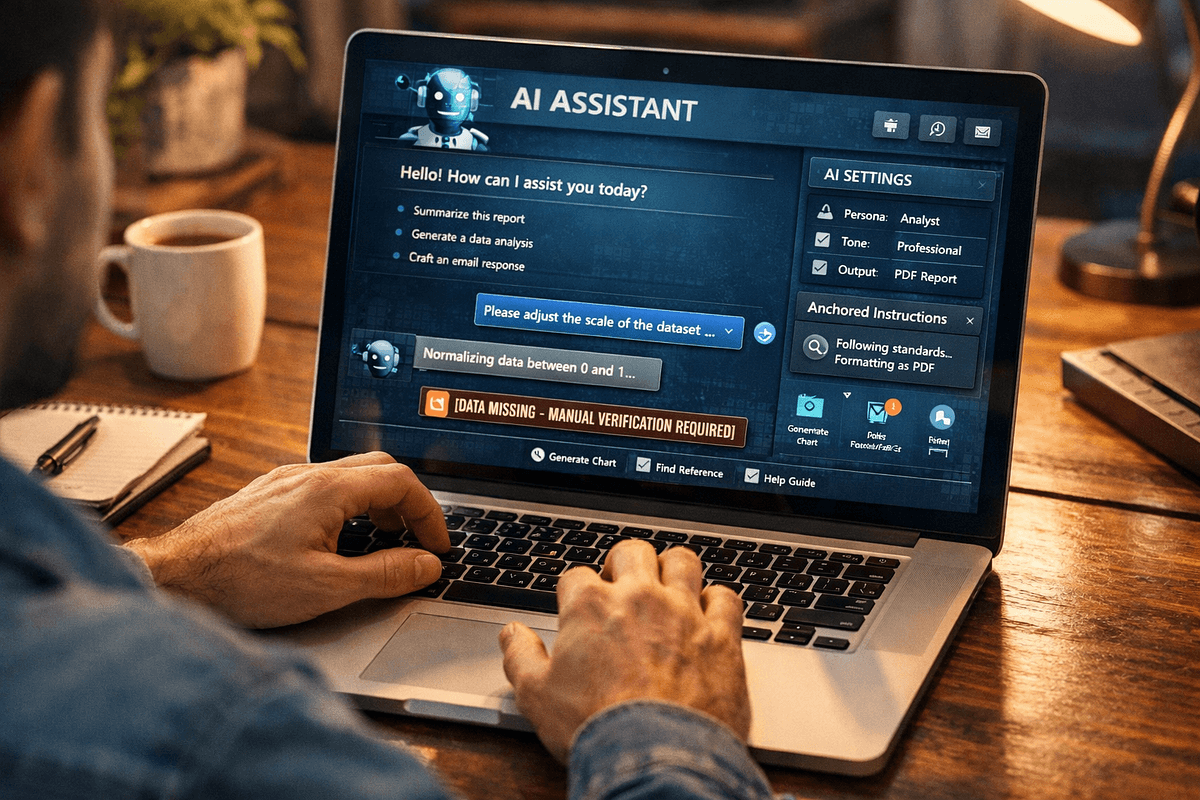
- Example: A data scientist asking to "adjust the scale" gets normalization (0-1 scale) when they meant map scaling (1:1000 to 1:500).
- The Hallucination Loop: When the model cannot verify a fact, it predicts a plausible guess. This is mechanical fluency, not truth.
- Fix: Use the Data Missing Kill Switch: "If uncertain, write [DATA MISSING — MANUAL VERIFICATION REQUIRED]."
- Contextual Drift: In a 50-turn conversation, the AI forgets the initial persona.
- Fix: Use the Instruction Anchor at the start of every message: "Before continuing confirm you are still operating as [Persona], following [Standard], and formatting as [Format]. Correct any drift."
The GCIPO Framework (System Design for Prompts)
To stop playing guesswork, architect your prompts using the GCIPO system. This is a 5-pillar structure designed to force the AI into a specific logical domain.
1. G — Goal (The Objective)
What is the result? Be specific.
- Bad: "Write a report."
- Good: "Generate a 5-page Preliminary Site Investigation report for a risk-averse commercial developer."
2. C — Context (The Environment)
Who is reading? What decisions will they make? What are the stakes?
- Context: "Stakeholders are lawyers and engineers. Flaws here lead to regulatory fines."
3. I — Inputs (The Raw Material)
What are you providing? What is missing?
- Inputs: "DataFrame with missing values in Income (right-skewed) and Age (normal)."
4. C — Constraints (The Guardrails)
What must it never do? What is the technical constraint?
- Constraints: "PEP8 compliant. Modular functions. [Data Missing Kill Switch] active."
5. O — Output Format (The Shape)
How must it look?
- Output: "Markdown with H2 headers, a summary table, and a bullet-pointed recommendation list."
🏗️ Architecture of the "Precision Logic Engine"
To visualize this as a system (not just a chat session), think of Prompting as an Input-Process-Output (IPO) system with a Control Loop.
- Input Parsing: The LLM tokenizes your GCIPO structure.
- Persona Initialization: It switches from "General Web Surfer" to "Senior Engineer/Analyst" based on your 'Context' and 'Goal'.
- Generation: It generates content within the bounds of 'Constraints'.
- The Critique Loop (Control): Before saving the output, you run it through a Red-Team Audit (explained below).
Failure to implement the Control Loop results in stack overflow of generic content.
🧑💻 Practical Value: Implementing the Iteration Trigger
The single highest-ROI technique in AI workflows is the Iteration Trigger.
Instead of asking the AI to execute immediately, force it to ask you clarifying questions first. This saves hours of rework.
Copy and Paste this to the end of your GCIPO prompt:
"Before you begin the task, analyze my requirements and list 3 to 5 clarifying questions that will help you produce a result that meets 100% of my professional standards. Wait for my response before generating the final output."
The Critique Loop (Red Teaming) Never accept the first result. Ask the AI to audit itself.
"Now, switch to a Senior QA Auditor persona. Calculate a Confidence Score (1-100) and list the top 3 technical risks in the text just generated."
If the AI gives you an 82 confidence score, it is telling you exactly where it hallucinated. You now have a specific instruction to fix that specific gap.
⚔️ Comparison: Vague Prompts vs. Structured Prompts
| Feature | Vague Prompt (Generic) | Structured Prompt (GCIPO) |
|---|---|---|
| Goal Clarity | Low ("Help me with...") | High ("Generate [Archetype] for [Scenario]") |
| Constraints | None ("Whatever works") | Strict ("PEP8", "Median Imputation") |
| Output Form | Fluid/Textual | Structured/Code/Table |
| Result | Average/Safe | Precise/Actionable |
⚡ Key Takeaways
- Quality is input-driven: Your AI outputs are only as good as the specificity of your AI prompting instructions.
- The Average Trap: LLMs default to the mean of their training data; you must narrow the search space to get outliers (high precision).
- Use GCIPO: Adopt the Goal-Context-Inputs-Constraints-Output framework for every complex task.
- Iterate, don't execute: Use the Iteration Trigger to demand questions before code generation.
- Audit yourself: Use the Red Team Critique Loop to force the AI to flag its own uncertainties.
🔗 Related Topics
- How to Actually Use ChatGPT for SQL Generation [BitAI Link Placeholder]
- The Complete Guide to Prompt Engineering in 2024 [BitAI Link Placeholder]
- Avoiding LLM Hallucinations in Production [BitAI Link Placeholder]
🔮 Future Scope
We are moving beyond simple prompting toward Agentic Workflows. Future iterations of AI will require not just high-quality inputs, but external tool capabilities (plugin-gating) to verify the constraints you set in Context. The GCIPO framework is already the foundation of that discipline.
❓ FAQ
Q: Does changing the model (e.g., to GPT-4) fix bad prompting? A: Improves it slightly, but does not fix "hollow" outputs caused by ambiguity. A better prompt on GPT-3.5 will often beat a bad prompt on GPT-4.
Q: Is GCIPO too long to write every time? A: It feels long initially (15 seconds), but saves 30-60 minutes in back-and-forth rework. It scales with your complexity.
Q: How do I handle creative tasks with strict formatting? A: The "Persona Vault" comes into play here. You set the Goal and Constraints rigidly, but use the Context to allow creative flair within those boundaries (e.g., "Sales pitch but legally vetted").
🎯 Conclusion
You are not bad at technology; the technology was never designed for lazy instructions.
By identifying the Average Output Trap and implementing the GCIPO system, you stop relying on the AI's basic predictive probability and start commanding its specialized knowledge. Treat your AI interactions like engineering specs, not casual conversations.
Ready to stop getting hollow results? Implement the Iteration Trigger on your next task and watch the quality jump.
This article was adapted from concepts in "The Precision Logic Engine" by John Kuram. It explores the intersection of prompt engineering and software system design.
Share This Bit